What to Look For in an AI SEO Agency Focused on GEO (A Skeptic’s Guide)
“AI SEO agency” has become a label that covers everything from “we can write faster” to “we can actually change what GPT-4o, Claude 3.5, and Gemini 2.0 say about you.” Those are not the same service. The reverse-angle problem is that most buyers evaluate GEO agencies using the easiest-to-fake evidence: pretty dashboards, a few cherry-picked screenshots, and a content calendar with a confident tone.
We (Lumonix) hire and partner with agencies the same way we evaluate any system: we try to break it. GEO lives in failure modes: missing citations, conflicting facts, negative framing, and model drift. If your agency can’t demonstrate how it detects and fixes those failures, you’re not buying optimization—you’re buying narration.
Key Takeaways (What matters when you’re paying real money)
Content output is not capability
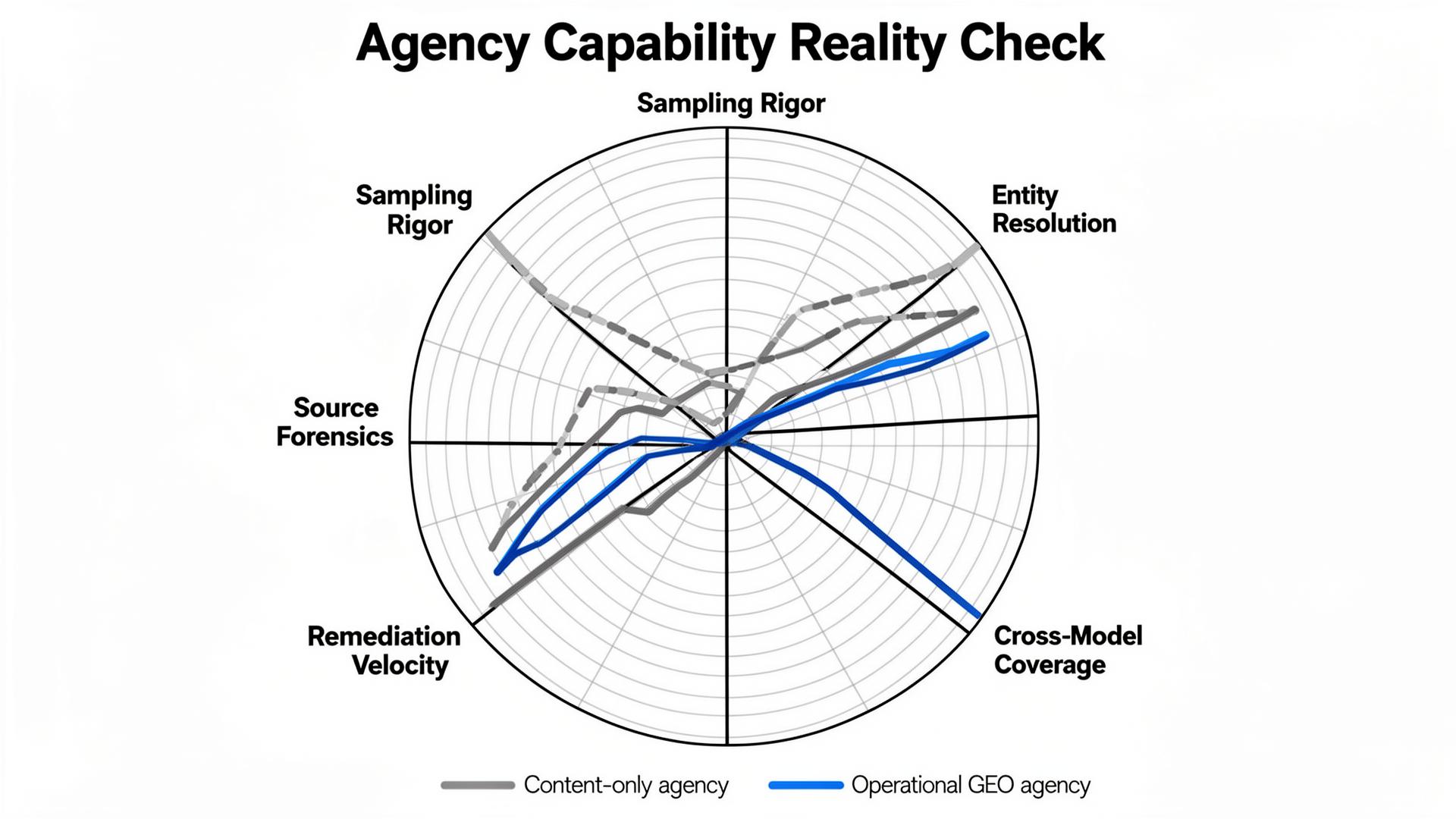
An agency can produce 500 posts a month and still fail at GEO if those posts never become retrieval targets, never resolve entity conflicts, and never change how models ground answers. Volume is easy. Diagnostics are not. The agency you want is the one that can show what they measure, how they sample, and what they change across the ecosystem—not just on your blog.
Entity work is measurable—if they’re doing it for real
Real entity optimization shows up as a reduction in contradictions across high-trust sources, improved source stability in citations, and fewer “unknown / unclear” statements in answers. If the agency can’t produce a conflict map (what sources disagree, which ones dominate retrieval, and which ones they will change first), they’re not doing entity work. They’re doing vocabulary.
Crisis protocols matter because hallucinations are reputation incidents
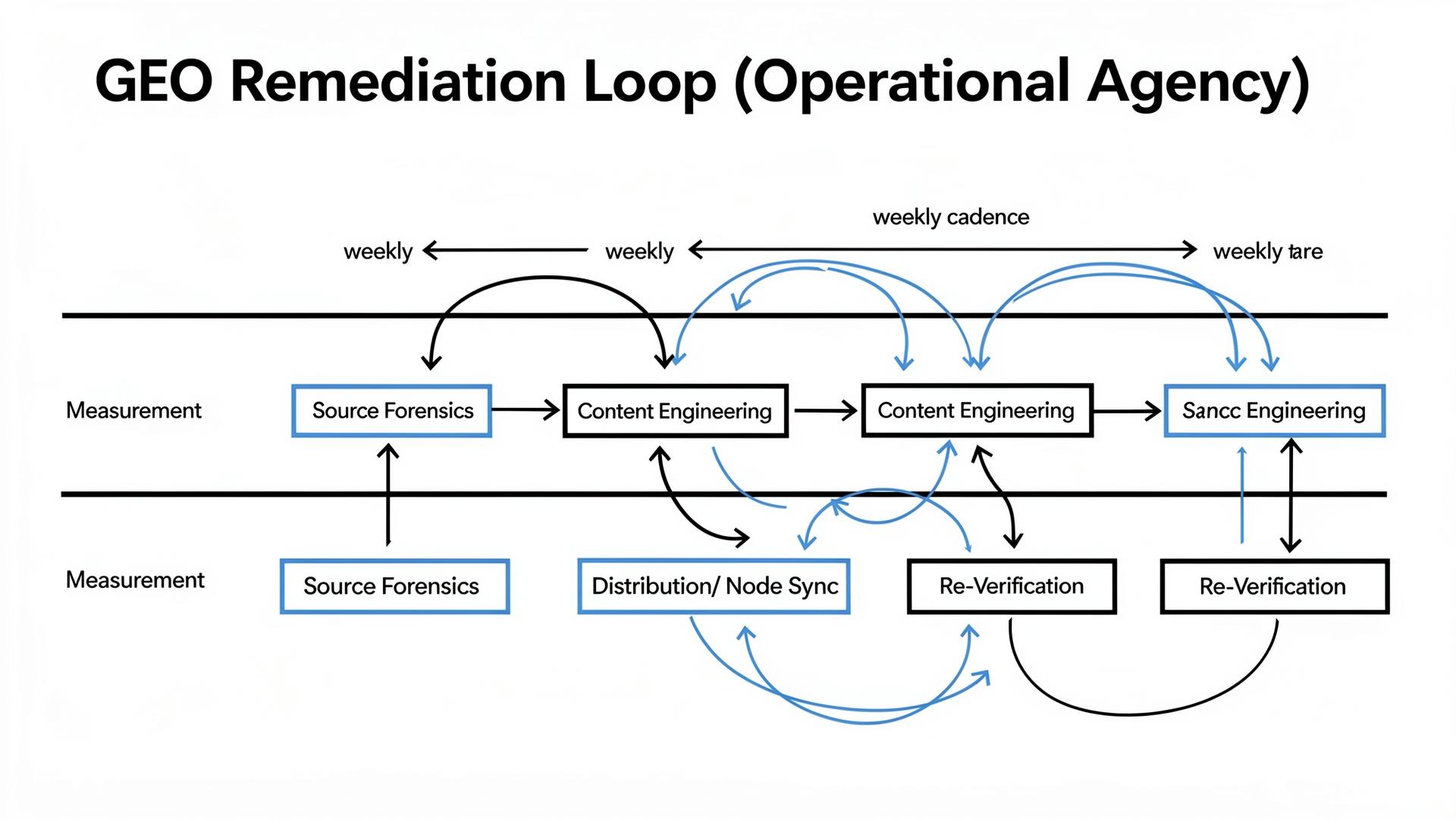
When a model repeats a false claim about your pricing, compliance, or capabilities, that’s not “noise.” It’s a brand incident. A serious agency treats this like incident response: thresholds, owners, source forensics, and a remediation loop. If they only offer “we’ll monitor,” they’re offering anxiety as a service.
The Skeptic’s Table: What Agencies Sell vs What You Should Demand
The offers that sound good (and the failure mode they hide)
Agencies sell what buyers recognize: content, schema, and rankings. GEO requires something buyers rarely ask for: source mapping, sampling methodology, and operational fixes. Use this table as a filter to force specificity.
| What they sell | How it breaks | What you should demand |
|---|---|---|
| “AI content at scale” | Low information gain; repetitive pages never become retrieval targets | Proof of retrieval for specific prompt clusters, plus a plan for semantic density and distribution |
| “We do GEO schema” | Schema is correct, but sources conflict elsewhere; models hedge or exclude | Entity Resolution plan: conflict map, external node sync, timestamps, and owners |
| “We track AI rankings” | One prompt + one model = false certainty | Sampling design: portfolio, variants, reruns, confidence bands, and cluster-level reporting |
| “We’ll improve citations” | Cited more often in irrelevant contexts; negative framing grows | Framing + objection taxonomy: “recommended vs caveat,” plus remediation tied to sources |
The Technical Layer: How RAG Turns Agency Work into Outcomes
RAG is a selection system; most agencies optimize the wrong stage
In retrieval-augmented generation, models retrieve candidate sources, rank chunks, and synthesize. Your agency can “optimize content” and still lose if the content is never retrieved, or if the chunk ranking prefers an external directory table, or if entity resolution flags contradictions. This is why we ask agencies to explain the retrieval target story: which sources are in the candidate set today, and why?
Semantic Density, Entity Resolution, Contextual Grounding—what they should do with them
Semantic Density is not “more facts.” It is more extractable facts in the top-ranked chunks: constraints, decision criteria, and tables that survive chunking. Entity Resolution is not “add a knowledge graph.” It’s removing contradictions across the nodes the model already trusts (docs, directories, reviews, partner pages). Contextual Grounding is not “hope for citations.” It’s building sources that can be used as evidence and then verifying that the model actually uses them across reruns and variants.
If an agency can’t connect those terms to specific deliverables (pages, node updates, performance fixes, distribution steps), they are selling a glossary, not a system.
“A GEO agency’s real output is not articles. It’s a reduction in ambiguity across the web about who you are, what you sell, and why you’re trusted.”
Lumonix CTO — Expert Insight
Lumonix Lab Case Study (Synthetic): The Agency That “Won” the Dashboard and Lost Reality
Baseline: impressive charts, weak inclusion in real prompts
A mid-market HR SaaS vendor (call them “Rosterly”) hired an agency that promised “AI visibility growth.” The agency delivered weekly charts, rising mention counts, and a handful of screenshots. Meanwhile, in the prompts that actually mattered—vendor comparisons with compliance constraints—Rosterly was missing or framed as “unclear security posture.” In our Lumonix Lab portfolio of 130 prompts, their qualified inclusion rate was 7%, and “unknown policy / unclear compliance” objections appeared in 22% of runs.
Step 1: Replace dashboards with a sampling plan and a prompt universe
We rebuilt measurement from scratch: clusters (discovery, comparison, procurement) plus variants (region, budget, compliance). We added reruns and confidence reporting. The first insight was uncomfortable: half the agency’s “wins” came from easy brand prompts. When we weighted the portfolio toward comparison and procurement prompts, the “visibility growth” mostly vanished. Good. Now we had a target that mapped to revenue reality.
Step 2: Do source forensics and resolve entity conflicts (the part content calendars ignore)
Source mapping showed that models grounded on an outdated security PDF and two directory listings with stale compliance notes. The site’s current security page existed, but it wasn’t retrieved consistently and wasn’t structured for extraction. We shipped a canonical security truth page with a constraints table and timestamps, then synchronized the top external nodes with the exact same claims. Entity Resolution improved because the ecosystem stopped disagreeing.
Step 3: Operationalize remediation velocity with owners and SLAs
Finally, we set a weekly remediation loop: identify top repeating objections → trace sources → ship corrections → re-run portfolio. Over six weeks, qualified inclusion rose from 7% to 23%, and compliance-related objections dropped from 22% to 9%. Citation stability improved as the canonical pages became consistent grounding targets. The “growth” wasn’t a vibe. It was a system change.
Common Wisdom vs. Reality (Three Mistakes Buyers Make When Hiring Agencies)
Common wisdom: “Show me case studies”
Case studies are narratives. Reality is diagnostics. Ask for sampling methodology, source mapping examples, and how they handle non-cited answers. A case study that doesn’t show failure modes is marketing.
Common wisdom: “We just need more content”
If your problem is retrieval and contradictions, content volume is a distraction. Reality is that many GEO wins come from making policies, pricing, docs, and constraints machine-verifiable and distributed—not from writing more blog posts.
Common wisdom: “Rankings will tell us if it’s working”
A single blended score will hide the truth. Reality is cluster-level outcomes: are you recommended in buying prompts, with fewer repeating objections, grounded in your sources? If the agency can’t report that, they can’t improve it.
Contract Notes: How to Pay an Agency for Reality (Not for Output)
Pay for remediation velocity and proof, not “deliverables”
If your SOW is mostly “X pages per month,” you’re paying for motion, not outcomes. A healthier structure is to define a prompt portfolio, define scoring rules (qualified inclusion, objection rates, source stability), and then pay for a weekly remediation cadence with documented source-level changes. Agencies who can’t operate that cadence will try to replace it with content volume because content is the only lever they can ship on schedule.
What “good reporting” looks like in GEO
Good reporting is not a blended score and a trend arrow. It is a decomposition: which clusters moved, which objections fell, which sources shifted, what was shipped, and what will be shipped next. This is where you can tell if you hired operators or narrators.
FAQ
What should a GEO agency deliver in the first month?
A baseline prompt portfolio, rerun methodology, source forensics (what sources dominate your narrative), an objection taxonomy, and a prioritized remediation plan with the exact pages/nodes to edit. If the first month is mostly content output, you’re not building a loop yet.
How do we prevent agencies from optimizing to vanity prompts?
You own the prompt universe. Define clusters that mirror your funnel and procurement constraints, then lock sampling rules and require reruns. If the agency chooses the prompts, the agency will choose the easiest wins.
A question to debate
If you had to pick, would you rather hire an agency that writes beautifully—or one that can show you exactly why the model doesn’t trust you yet, and what they’ll change this week to fix it?