What’s the Best AI Visibility Tracker? The Wrong Question (Here’s the Picky One)
If you’re shopping for the “best AI visibility tracker,” you already feel the problem: classic monitoring assumes you can observe the whole funnel. In LLM ecosystems, you can’t. But the reverse-angle problem is worse than invisibility. Many trackers give you precise-looking numbers that are statistically meaningless, then call that “insight.”
We (Lumonix) don’t hate dashboards. We hate dashboards that push teams into the wrong work. A good tracker is not the one with the nicest UI. It’s the one that can answer three uncomfortable questions: What changed? Why did it change? What do we edit, and where, to change it back?
Key Takeaways (Explained like you’ll actually use them)
“Mentions” are not visibility; they’re often a warning label
A model can mention you as the expensive option, the risky option, or the “not recommended if…” option. If a tracker counts those as wins, it will reward the exact outcome you’re trying to avoid. What you want is qualified inclusion: being recommended in prompts that match real buying contexts, with the right constraints and objections addressed.
One prompt is not a dataset; variance is the product
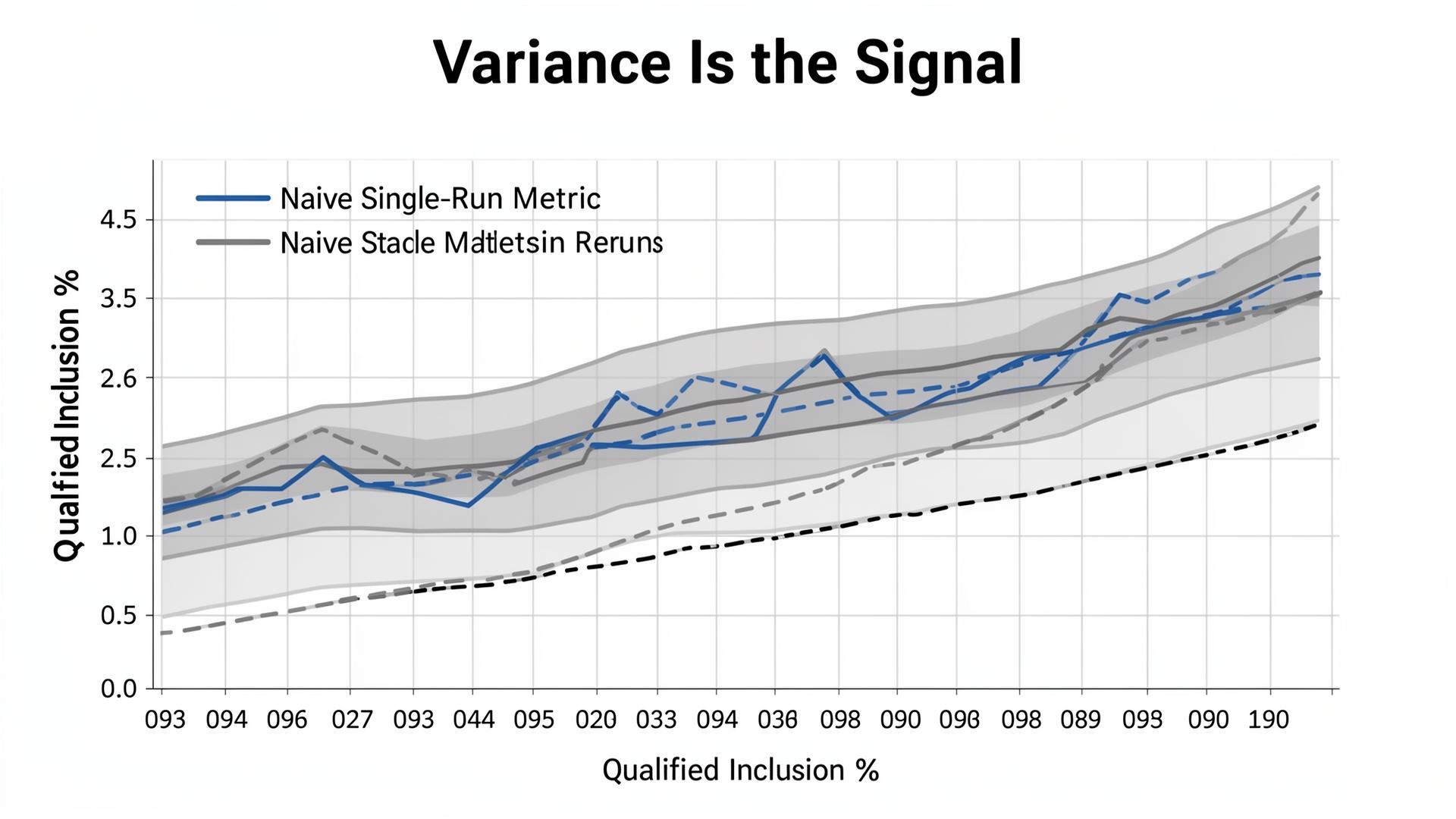
GPT-4o, Claude 3.5, and Gemini 2.0 do not produce deterministic outputs. Prompt phrasing, constraint framing, and retrieval sources change outcomes. The tracker you buy must treat variance as signal: it should show reruns, confidence bands, and prompt-cluster breakdowns so you can distinguish “real lift” from “prompt luck.”
Truth errors beat sentiment as a risk metric
Positive sentiment wrapped around a wrong claim is a brand incident waiting to happen. If a tracker cannot identify wrong product claims, outdated policies, or hallucinated capabilities, it’s not a visibility tool. It’s a feel-good chart generator. The hard metric is grounded correctness, not vibes.
The Evaluation Framework: What to Test in a Tracker (Before You Fall in Love)
Sampling design: can it survive a portfolio change?
If the vendor’s “tracking” is a single hero prompt, they’re not measuring performance; they’re measuring a single sentence. The minimum bar is a prompt portfolio with clusters (discovery, comparison, transactional) and systematic variants (budget, region, compliance, integration constraints). A serious system should tell you what happens when your prompt mix shifts, because your buyers’ prompt mix will shift.
Forensics: can it explain sources and missing citations?
When citations are present, mapping is straightforward. The real test is when citations are missing or inconsistent. If the tool can’t infer likely source sets, diagnose retrieval targets, and recommend remediation, it can’t close the loop. You’ll become a team that “monitors” without fixing.
| Capability you should demand | How weak tools fake it | What a real system must show |
|---|---|---|
| Portfolio sampling + reruns | One prompt, one model, one time window | Variant count, rerun count, confidence bands, cluster-level reporting |
| Source mapping | Only shows “mentions” without citations | Cited URL distribution, source deltas over time, retrieval-target hypotheses |
| Claim validation | Sentiment scoring as “quality” | Extract claims, check against truth layer, flag high-impact wrongness |
| Multi-model normalization | Compares raw counts across models | Per-model baselines, consistent prompt sets, normalized scoring |
The Technical Layer: How RAG Turns Your Brand into Numbers
RAG is a pipeline with bottlenecks, not a magic citation machine
In many experiences, the model is effectively doing retrieval-augmented generation (RAG): it retrieves candidate sources, ranks them, extracts chunks, and then synthesizes an answer. Your “visibility” is a side effect of whether your sources enter the candidate set and whether your chunks are selected as grounding evidence. That selection is constrained by latency budgets, token budgets, and trust heuristics. A tracker that pretends the output is deterministic is measuring the wrong system.
Where Semantic Density, Entity Resolution, and Contextual Grounding actually matter
Semantic Density determines whether the retrieved chunks contain quotable facts. If your key constraints live in prose, chunking can bury them and the model will ground itself in someone else’s table. Entity Resolution determines whether the model can consistently map “you” across docs, listings, reviews, and competitors. If those nodes conflict, systems often hedge or exclude you to reduce risk. Contextual Grounding determines whether the model can attach claims to stable sources; when grounding is weak, hallucinations rise and the model leans on “safe” third-party nodes.
A serious tracker should reflect those mechanics. It should not just say “mentions up.” It should show you whether you’re being retrieved, whether your sources are stable, and whether the model is grounding claims correctly.
“A tracker that can’t show variance is not a tracker. It’s a marketing dashboard. If the output is probabilistic, your measurement must be statistical.”
Lumonix CTO — Expert Insight
Lumonix Lab Case Study (Synthetic): When the Dashboard Looked Great—and the Model Was Wrong
Baseline: “mentions up,” but the model repeated a false capability
A B2B security vendor (call them “VaultNorth”) came to Lumonix Lab after buying a tracker that reported “visibility growth.” Their marketing team was calm. Their sales team was furious. In commercial prompts, the model repeatedly claimed the product supported a compliance feature that had been retired. The tracker scored it as positive sentiment and a mention. Reality: it was a high-impact false claim, and the wrong buyers were showing up with the wrong expectations.
Step 1: Redesign the measurement to separate inclusion from correctness
We rebuilt the portfolio to include the prompts that mattered (implementation and compliance constraints), then added claim extraction and a truth-layer reference. Instead of “mention rate,” we tracked “qualified inclusion” and “critical claim error rate.” In the baseline run, qualified inclusion was 4% and critical claim error rate was 13% across 140 prompt variants. The “visibility score” had hidden the risk.
Step 2: Fix the sources the model actually grounded on (not just the homepage)
Source forensics showed the model grounding on an old PDF, a partner blog post, and a review directory listing that still described the retired feature. We shipped a canonical fact sheet with a constraints table, replaced the PDF with an HTML page, and synchronized the top external nodes with the same “supported vs not supported” language. This was entity work plus distribution, not content marketing theater.
Step 3: Verify lift with reruns, then lock the remediation loop
After three weekly remediation cycles and reruns across variants, qualified inclusion moved from 4% to 19% in compliance-oriented prompts, and critical claim error rate dropped from 13% to 3%. Citation stability improved as the canonical fact sheet became the dominant grounding node. The team’s “visibility” didn’t just increase; it became safer and more durable.
Common Wisdom vs. Reality (Three Bad Pieces of Advice Trackers Accidentally Reinforce)
Common wisdom: “Pick one model; it represents the market”
A single-model dashboard is cheap, neat, and misleading. Buyers fragment across ecosystems. A tracker that can’t normalize cross-model results is not saving you money; it’s saving you from learning the truth.
Common wisdom: “Composite scores make reporting easier”
Composite scores are board-friendly, but they collapse different failure modes into one number. If you can’t decompose variance, source shifts, and objection framing, you can’t diagnose. If you can’t diagnose, you can’t fix.
Common wisdom: “Positive sentiment means you’re winning”
Positive-but-wrong is worse than neutral-but-correct in commercial prompts. Trackers that reward sentiment over truth encourage teams to optimize tone while the model repeats the wrong facts. That’s how you end up with “great visibility” and terrible pipeline.
FAQ
What should we demand in a trial of an AI visibility tracker?
A defined prompt portfolio, rerun counts, confidence reporting, source mapping, and a demonstration of how the tool handles missing citations and wrong claims. A trial that only shows a dashboard is not a trial; it’s a sales demo.
If we can’t see private user chats, can we still measure GEO outcomes?
You can’t observe everything, but you can design a synthetic portfolio that mirrors buyer intents and constraints, then measure inclusion, framing, sources, and claim correctness over time. The goal isn’t omniscience; it’s a reliable loop that turns measurement into source-level fixes.
A question to debate
If your tracker says “mentions are up,” but your sales pipeline is full of buyers who believe a wrong claim about your product, do you trust the dashboard—or do you redesign the metric around truth?