CES 2026, AI Agents, and the Uncomfortable Truth: “Appearing” Might Be a Trap
CES 2026 didn’t just show “AI is coming.” It showed a more uncomfortable shift: we’re moving from conversational answers to agentic execution. In conversational search, you could win by being quotable. In agentic search, you win by being safe to act on. The reverse-angle reality is brutal: the “best” brand for an agent isn’t the most persuasive—it’s the least risky. That changes how visibility works, how conversion happens, and why your analytics will start lying to you (politely).
We (Lumonix) care about this because “agent readiness” is one of those phrases that makes teams feel productive while they do the wrong work. If your readiness plan is “add schema, write a page about agents, and hope,” you are preparing for the demo, not the reality. Reality is latency budgets, policy ambiguity, conflicting facts across the web, and the awkward possibility that the agent converts a user without ever visiting your site.
Key Takeaways (No bullets, because agents don’t care about your formatting)
Agents punish ambiguity more than they reward branding
If your return policy lives in a PDF, your warranty terms are “contact sales,” and your pricing is “book a call,” an agent sees you as unknown risk. Humans might tolerate that friction. Agents won’t. They optimize for execution success, not for your funnel narrative.
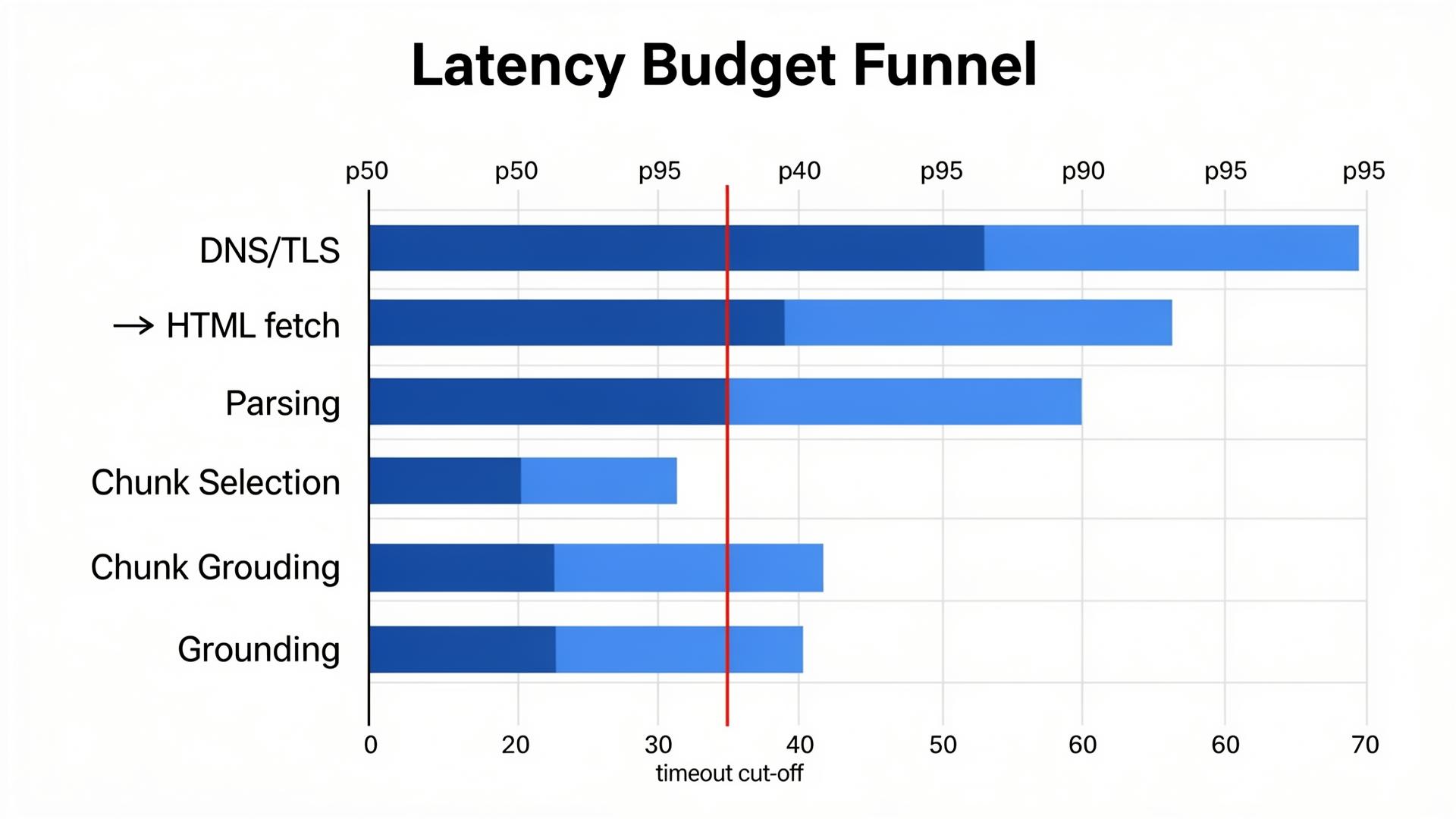
Latency becomes a ranking factor when the output is an action
When an agent needs to decide “which provider can complete this task,” slow pages and slow APIs are not just a UX problem. They are exclusion criteria. A brand can be “best in class” and still be skipped because retrieval timed out.
Zero-traffic conversions are real—and your dashboards may never see them
In an agentic flow, the user may never click. The agent might book, buy, or recommend inside another surface. If your measurement stack equates “click” with “influence,” you will undercount impact and overinvest in the wrong levers.
Where Agent Readiness Breaks in Practice
The hidden constraints: timeouts, conflicts, and proof
Most teams focus on content and schema because those are familiar. Agents care about harsher constraints: they must act fast, avoid contradictory facts, and justify actions with machine-verifiable policies. If you can’t be verified, you’re not “trusted,” you’re “expensive risk.”
A practical constraints table (because agents love boring clarity)
| Constraint | Failure mode | Lumonix fix (what we actually ship) |
|---|---|---|
| Latency budget | Agents skip slow pages/APIs; your “best” page never gets retrieved. | Measure p95 retrieval + render time; publish lean agent-ready pages; cache critical endpoints. |
| Fact conflicts | Pricing/shipping/policy differs across sources; agent excludes you to reduce risk. | Entity consistency audit + distributed corrections across high-trust nodes. |
| Execution proof | Your offer cannot be verified programmatically; competitor wins by default. | Expose structured availability, policy terms, and identifiers; align with documentation and third-party listings. |
The Technical Layer: How GPT-4o / Claude 3.5 / Gemini 2.0 Make an Agentic Choice
RAG under action pressure: candidate sets get smaller, not bigger
In agentic experiences, the system often uses retrieval-augmented generation (RAG) in a more constrained way than people expect. The model (GPT-4o, Claude 3.5, Gemini 2.0) must retrieve sources quickly, rank them, and ground decisions in evidence. Under action pressure, candidate sets shrink. Retrieval budgets (latency and tokens) push the system toward sources that are easy to fetch and easy to quote. That’s why your glossy homepage hero section is irrelevant: the agent is reading the parts of your ecosystem that survive retrieval constraints.
Three technical terms your “agent readiness” vendor must not misuse
Semantic Density matters because agents need extractable facts: policies, constraints, and operational details. If your pages are long but low-density, chunking hides what matters, and the agent grounds its decision in someone else’s table.
Entity Resolution matters because agents must map “this vendor” across docs, listings, reviews, and marketplaces. Conflicts don’t just reduce ranking; they increase perceived risk. Under risk, agents choose safer defaults.
Contextual Grounding matters because an agentic decision needs traceable justification. If the system cannot ground “this vendor supports X” in a stable source, it either hedges (“it depends”) or it chooses the vendor with more verifiable, structured evidence.
“Agentic search will make marketing teams uncomfortable: the most important consumer might be a bot that never sees your homepage hero section.”
Lumonix CTO — Expert Insight
Common Wisdom vs. Reality (What People Optimize, vs What Agents Actually Use)
Common wisdom: “Get more mentions; that’s agent readiness”
Mentions are cheap. An agent can mention you as a warning label. The reality is that agentic outcomes depend on execution success rate, not mention volume. If you don’t track whether the agent can complete the task (book, buy, configure, integrate), you’re counting noise and calling it progress.
Common wisdom: “Publish one perfect page and you’re done”
Agents assemble decisions from ecosystems. One perfect page does not outvote dozens of conflicting third-party nodes. Reality is distributed: policy statements in PDFs, marketplace listings, review snippets, and outdated docs can dominate grounding. Agent readiness requires a distribution and synchronization plan, not a single content deliverable.
Common wisdom: “Optimize for clicks because clicks are conversion”
In agentic search, conversions can happen without clicks. A user can become “converted” mentally by the agent’s recommendation, or the agent can complete the action elsewhere. The reality is that your influence can rise while your traffic stays flat. If you punish teams for that, they will optimize for traffic theater and lose agentic selection.
Lumonix Lab Case Study (Synthetic): When “Appearing” Didn’t Convert
Baseline: high visibility, low selection
A consumer retail brand (call them “ArcadeHome”) showed up frequently in AI answers for broad discovery prompts. Their team celebrated because mentions were up. Our Lumonix Lab portfolio testing told a different story: in 90 action-oriented prompts (“best option under $X,” “buy with fast returns,” “ship to region Y”), the agent recommended competitors more often. ArcadeHome was mentioned, then qualified away: “unclear returns,” “shipping unknown,” “pricing varies.” Their qualified inclusion rate in action prompts sat at 6%, despite mention volume looking healthy.
The real culprit was grounding. The agent’s answer assembled a narrative from third-party sources and old PDFs. Even when the brand’s site had correct policies, the policies were not easily retrievable or extractable. Semantic density was low, and the agent couldn’t confidently ground execution decisions in stable URLs.
Step 1: Replace PDF policies with extractable truth blocks
We moved returns and warranty terms from PDFs to a fast HTML page with structured sections and a compact table. We added explicit timestamps and made the page a stable internal target linked from high-intent pages. This increased semantic density and improved grounding. The key change wasn’t “more content.” It was making the content usable under retrieval constraints.
Step 2: Resolve conflicts across the ecosystem (Entity Resolution)
Next, we mapped contradictions in marketplace listings and review sites, then synchronized the same policy and shipping constraints across the top-cited nodes. This reduced “unknown” and “varies” language. Agents are risk-averse; when sources agree, agents stop hedging.
Step 3: Monitor action readiness, not vanity visibility (Contextual Grounding)
Finally, we changed the KPI: instead of counting mentions, we tracked “unknown policy” responses and “action completion confidence.” In reruns across the portfolio, ArcadeHome’s “unknown policy” answers dropped by 41%, and qualified inclusion in action-oriented prompts rose from 6% to 18% over 5 weeks. Traffic barely changed. Selection did.
What to Track Next: The Reverse-Angle KPI Stack for Agentic Search
Execution confidence (can the agent safely act?)
If the agent cannot confidently answer “what happens if the user returns this” or “what are the constraints,” it will prefer a vendor with clearer, grounded policies. Execution confidence is shaped by extractable truth blocks and source consistency, not brand copy.
Source stability (do the same trusted URLs keep showing up?)
A single “win” is meaningless if citations drift each week. Track whether your canonical pages remain in the retrieved set and whether third-party nodes are aligned. Stability predicts durability; volatility predicts you’re renting influence from someone else’s forum post.
FAQ
Is agent readiness just “having an API”?
No. APIs help execution, but agents still need grounded proof: policies, constraints, identifiers, and stable truth pages. Without semantic density and entity consistency, an API is just a fast way to be ignored.
Why would agents exclude a well-known brand?
Because well-known does not mean verifiable. If the ecosystem contains conflicting facts, or if the agent cannot ground execution decisions in stable sources, the safest choice is exclusion or qualified recommendation. Agents optimize for minimizing user harm, not maximizing brand fame.
A question to debate
If agents start buying on behalf of users, should your growth team optimize for traffic—or for machine-verifiable trust even when attribution looks worse?