Choosing a GEO Company? Here’s Where Your “Perfect Checklist” Breaks
Everyone says they “do GEO” now. That’s not the crisis. The crisis is that most RFPs still evaluate GEO like it’s 2018 SEO: content volume, generic schema checklists, and screenshots that look impressive on a slide. In practice, the best GEO company is the one that can reduce retrieval failure, contain hallucination narratives, and prove causal lift across a prompt universe—not the one that can write the nicest deck.
We (the Lumonix team) tend to be annoyingly picky about this because we’ve watched the same pattern repeat: buyers select vendors who can describe the system, not vendors who can operate it. If you want a partner that actually moves AI citations, you need an RFP that forces a vendor to demonstrate how they diagnose failures, how they edit the real sources models use, and how they confirm that changes stick under model drift.
Key Takeaways (In prose, because real life doesn’t fit a bullet list)
Your checklist is selecting storytellers, not systems engineers
If your evaluation rewards “we track AI rankings” and “we fix your schema,” you’re selecting the vendor who is best at reporting outputs. GEO outcomes are probabilistic. A vendor who can’t show variance, sampling design, and a remediation workflow is essentially selling you confidence, not a process.
The differentiator is closed-loop operations, not vocabulary
Every vendor can say “embeddings” now. The question is whether they can run a loop: measure → diagnose → change source-of-truth → distribute corrections → re-measure → catch regressions. If they can’t explain what they ship each week and why it should change retrieval or framing, you’re buying a monthly report with better typography.
The Evaluation Table: Claims, Failure Modes, and the Only Questions That Matter
What vendors claim (and how it breaks)
Most RFP responses are written as happy-path narratives: “We improved visibility by X%.” Great. Now ask: what happens when citations disappear, when a model answers without citations, or when a competing source becomes the default retrieval target? Vendors who can’t handle those scenarios won’t help when your pipeline depends on them.
What to ask instead (so the demo can fail)
| Vendor claim | Where it fails in production | RFP question that forces reality |
|---|---|---|
| “We track your AI rankings.” | They sample one prompt, one model, one time. Variance gets mislabeled as “trend.” | “Show your sampling plan, rerun count, and confidence bands. What changes when you swap 30% of prompts?” |
| “We fix your schema.” | Schema is correct, but the page is not retrieved or is outranked by review nodes. | “Which pages are retrieval targets for these prompt clusters, and why? Prove retrieval, not correctness.” |
| “We improve citations.” | Citations rise for irrelevant prompts, or framing becomes negative (“good but…”). | “Show a before/after by prompt cluster and objection taxonomy, not one blended number.” |
| “We do entity optimization.” | They “clean” on-site terms while third-party sources keep conflicting facts. | “Map the conflicting nodes. Which external sources dominate retrieval, and what is your distribution plan?” |
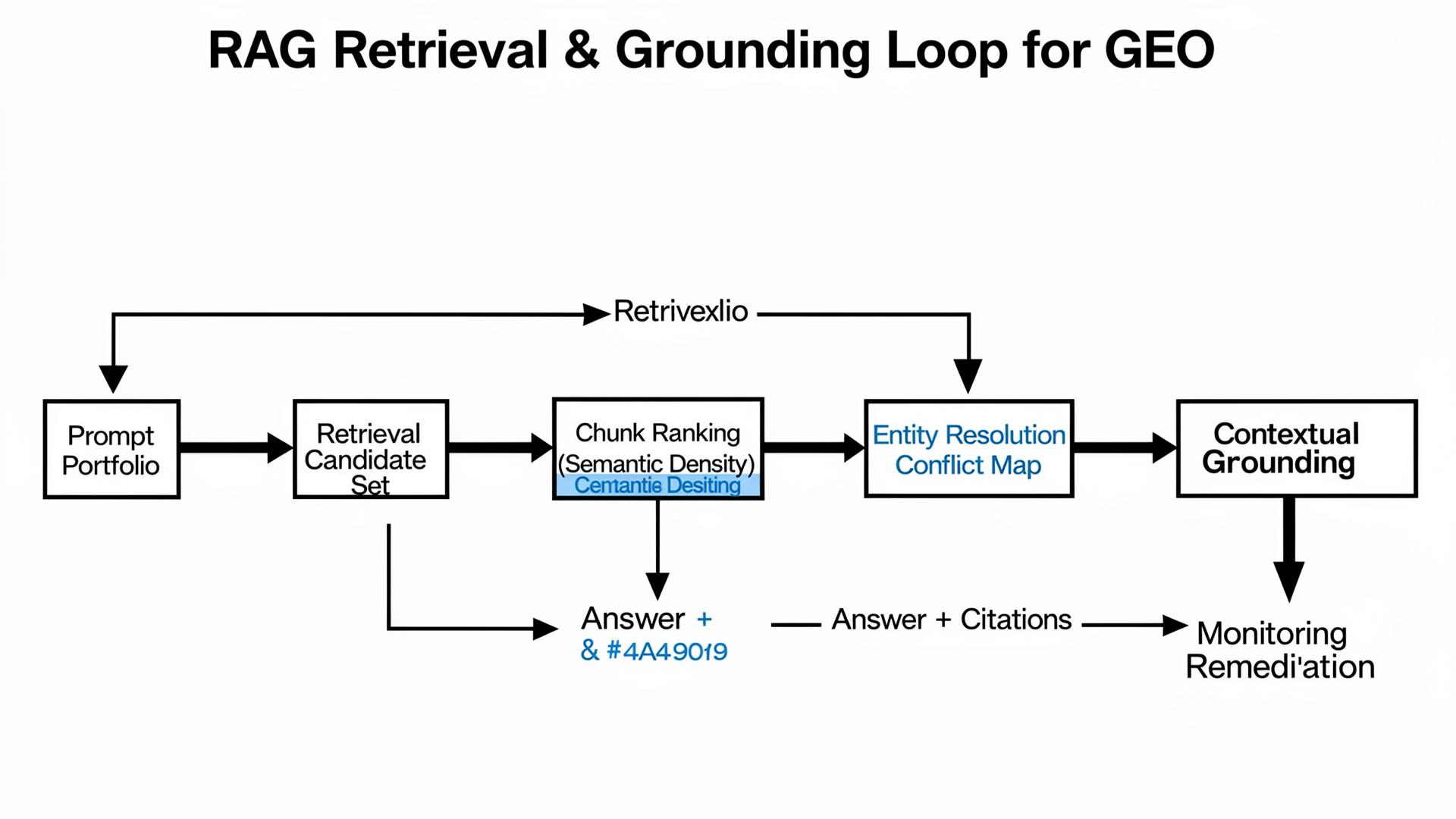
The Technical Layer: How RAG Systems Decide Whether You Exist
RAG is not “search then write.” It’s “retrieve under constraints”
When GPT-4o, Claude 3.5, or Gemini 2.0 answer a commercial question, the system is often doing retrieval-augmented generation (RAG) implicitly or explicitly: it builds a candidate set of sources, ranks them, extracts chunks, and then synthesizes a response. The uncomfortable part is that retrieval has budgets: latency, token limits, and heuristics that prefer sources that look stable and easy to quote. If your best page is slow, inconsistent, or semantically “thin,” it may never enter the candidate set.
This is why “we wrote more content” is usually a weak GEO answer. In retrieval, availability beats quality. A page that’s 80% as good but 10× easier to retrieve can dominate citations. That’s not philosophy. That’s systems design.
Three technical levers your vendor must understand
Semantic Density is the concentration of extractable, verifiable claims per token. Models and retrieval pipelines favor content that yields clean facts quickly: tables, definitions, constraints, and “source-of-truth” blocks. If your page is long but low-density, chunking can hide your key claim in paragraph 19 where it gets sliced out of the top chunks.
Entity Resolution is how the system maps “you” across the ecosystem: your brand name, product name variants, and claims across docs, review sites, and directories. If those nodes conflict, the model often reduces risk by excluding you or framing you with caveats. The vendor you hire must be able to produce a conflict map and a correction plan, not just “update the website.”
Contextual Grounding is the mechanism that ties generated statements back to supporting evidence. When grounding is weak (missing citations, thin sources, conflicting claims), models hedge or hallucinate. GEO work is largely the craft of strengthening grounding: publish constraints, update canonical facts, and ensure the sources models retrieve are consistent enough to support a confident, accurate narrative.
“If your vendor can’t explain how an answer was assembled—candidate sources, chunk selection, and why one source outranked another—then they can’t fix it. They’re guessing with better branding.”
Lumonix CTO — Expert Insight
Common Wisdom vs. Reality (A Gentle Roast of Bad GEO Advice)
Common wisdom: “Just add schema and you’ll be cited”
Schema can help extraction. It cannot force retrieval. If the system retrieves a review directory instead of your page, your perfect schema sits unused like a beautifully labeled box that never arrives at the warehouse. The reality is that schema is a multiplier: it magnifies a page that’s already retrieved and trusted. It doesn’t create trust out of thin markup.
Common wisdom: “Track mentions; more mentions means better GEO”
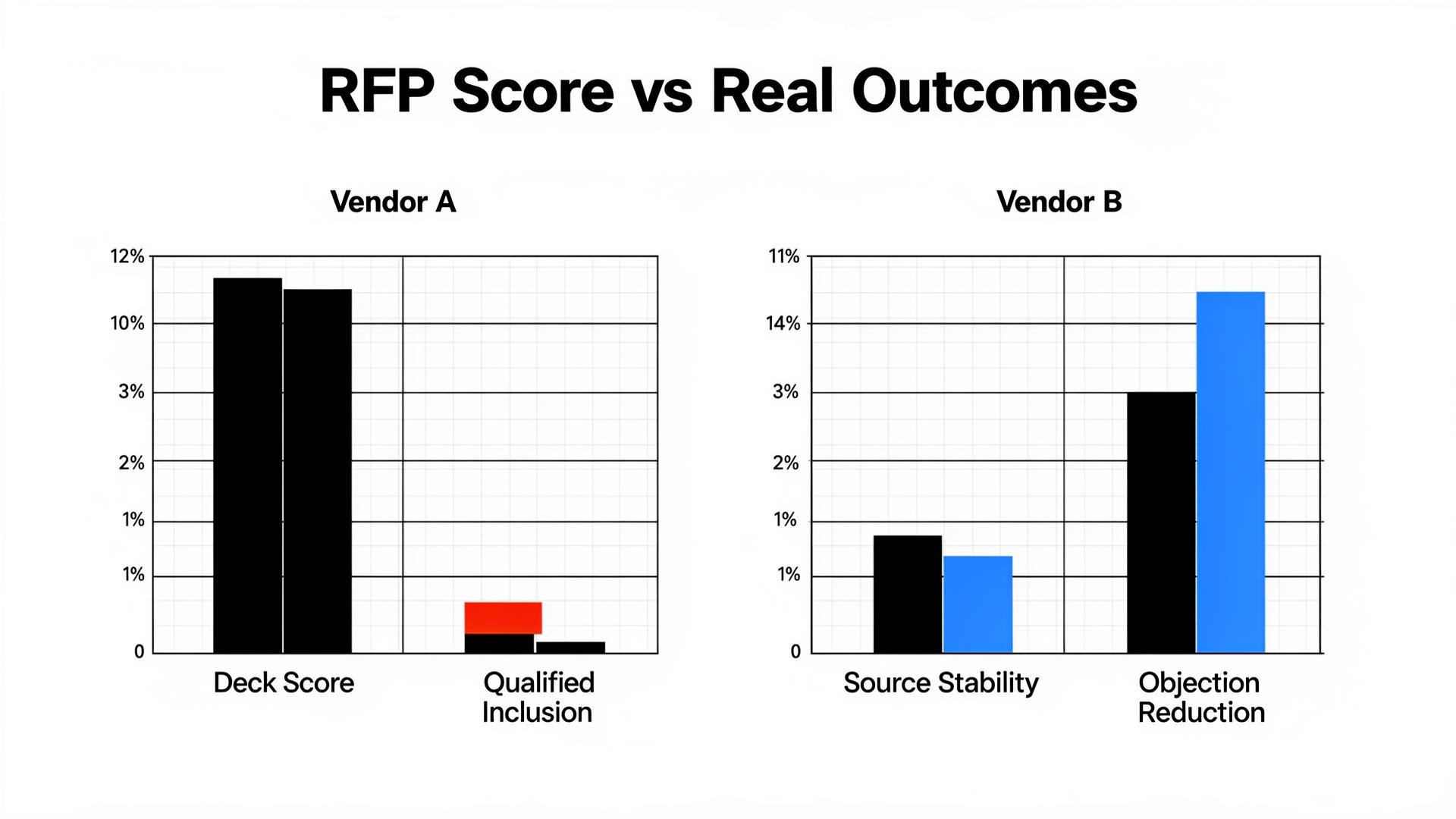
Mentions can be warnings. We’ve seen brands “improve visibility” while the model repeatedly frames them as expensive, risky, or hard to implement. A serious vendor tracks qualified inclusion (being recommended in buying contexts), objection rate (the “good but…” sentences), and source stability (which nodes control the narrative). If a vendor can’t show those layers, they’re selling a scoreboard that rewards the wrong game.
Common wisdom: “Publish more thought leadership”
Thought leadership is often low semantic density. It’s written to be inspiring, not extractable. In commercial RAG flows, the winners are boring: pricing boundaries, integration lists, compliance statements, and crisp comparison tables. If your vendor’s plan is “20 posts a month,” ask where those posts sit in the retrieval graph and which prompt clusters they are meant to move. If they can’t answer, you’re buying volume without effect.
Lumonix Lab Case Study (Synthetic, but realistic): From “Invisible” to “Cited with Confidence”
The problem: the model knew the category, not the brand
A mid-market B2B analytics brand (let’s call them “Northbeamry,” because we enjoy avoiding legal emails) came to Lumonix Lab with a familiar complaint: “We show up in Google, but in AI answers we’re missing—or we’re mentioned as a ‘maybe.’” Their internal team had already done the classic SEO tasks: rewrote blog posts, added schema, even published a 6,000-word “ultimate guide.” The result was… motivational. Not measurable.
In our baseline portfolio of 120 prompts (discovery, comparison, and transactional), their qualified inclusion rate was 4%. When they were mentioned, the dominant framing was “unclear pricing” and “integration limitations,” pulled from third-party nodes and an outdated help doc. Worse, citation sources were unstable: week to week, the model’s supporting URLs shifted, which meant even when they “won,” the win didn’t stick.
Step 1: Build a truth layer with high Semantic Density
First, we created a canonical “Fact Sheet” page that compressed the decision criteria into a small, extractable surface: pricing boundaries, supported integrations, security posture, and “who this is not for.” We didn’t write marketing prose. We wrote machine-quotable facts, with timestamps and a structured table. The goal was not beauty; it was retrieval utility. Semantic density went up, chunking got friendlier, and the page became a legitimate retrieval target.
Step 2: Resolve entity conflicts across external nodes (Entity Resolution)
Second, we mapped contradictions across the ecosystem: review directory listings, marketplace pages, old PDFs, and a partner blog that still described a retired plan tier. This is the part most vendors skip because it’s not “content marketing.” We updated the highest-impact nodes first (the ones that dominated citations in our source forensics) and aligned the exact same constraints language across them. Entity resolution improves when the ecosystem stops disagreeing about what you are.
Step 3: Close the loop with grounded monitoring (Contextual Grounding)
Third, we instrumented monitoring as a grounding check, not a vanity chart. For each prompt cluster, we tagged whether answers were cited, which URLs were used, and whether objections repeated. When a model answered without citations, we treated it as a diagnostic: either the retrieval target was weak, or the content wasn’t extractable enough to be used as grounding evidence. We shipped weekly corrections and re-ran variants to confirm lift was real, not prompt luck.
Results: fewer vibes, more measurable inclusion
After 6 weeks, the brand’s qualified inclusion rate in the portfolio moved from 4% to 19%. Citation frequency increased by 27% in the prompt clusters that mattered (comparison and transactional), while “unclear pricing” objections dropped by 31%. The most important metric was durability: source stability improved, meaning the model kept using the same canonical nodes instead of drifting to random forums. That’s what a real GEO partner should be optimizing for.
How to Write an RFP That Selects the Right GEO Partner
Force methodology: portfolios, reruns, and variance
Ask every vendor to define your prompt universe with you, then commit to reruns. If they can’t explain how many variants they run and how they separate signal from noise, they can’t prove outcomes. A vendor who refuses uncertainty is the one most likely to sell you fake certainty.
Force forensics: “why aren’t we cited?” must have a concrete answer
Make the vendor show a retrieval narrative: which sources dominated, which pages were ignored, and what they would change first. “We’ll write more content” is not an answer. “This review node is outranking your docs; we’ll publish a canonical table, then synchronize top nodes, then verify grounding improvements” is an answer.
FAQ
Do we still need classic SEO if we’re doing GEO?
Yes. Think of SEO as discovery and legitimacy. GEO is the selection and framing layer. If crawl/index health is broken, you’re harder to retrieve. If entity consistency is broken, you’re harder to trust. They’re connected systems, not competing religions.
What’s the fastest win if our brand is never cited?
Build a canonical truth layer with high semantic density (tables, constraints, timestamps), then distribute the same facts to the external nodes that models already cite. The “fast win” is rarely a new blog post. It’s removing contradictions that make the model hedge or exclude you.
What should we demand in the first 30 days from a GEO agency?
A baseline prompt portfolio, a source forensics report (which URLs/nodes dominate your narrative), an objection taxonomy, and a remediation plan that lists the exact pages/nodes to edit. If you get only a dashboard and a content calendar, you hired a reporter, not an operator.
A question to debate
Would you rather be cited less often but consistently in the right buying contexts—or be mentioned everywhere with ambiguous, unqualified sentiment that makes you sound like a risky default?