GEO Best Practices for Content Marketing (The Part Everyone Ignores)
“Add schema, increase fact density, use tables.” Great advice—until your content still isn’t cited. The reverse-angle truth isn’t that best practices are wrong. It’s that teams apply them to the wrong assets, in the wrong order, and then wonder why a model (GPT-4o, Claude 3.5, Gemini 2.0) keeps quoting someone else’s page.
We (Lumonix) treat GEO content as content engineering, not content publishing. Engineering has an uncomfortable property: inputs must map to the system’s bottlenecks. In RAG-style selection, the bottlenecks are retrieval targets, chunk selection, and trust signals distributed across the ecosystem. If your “best practice” doesn’t change any of those, it’s decorative.
Key Takeaways (Explained like you’re going to ship something)
Structure helps retrieval—but retrieval is not guaranteed
Tables, lists, and definitions improve extractability. But models can only extract what they retrieve. If your content isn’t in the candidate set, perfect structure is like printing a menu and forgetting to open the restaurant. The first GEO question is not “Is the page well structured?” It’s “Is this page a retrieval target for the prompt clusters we care about?”
Fact density without fact legitimacy can backfire
High Semantic Density (lots of facts per token) is good only if the ecosystem agrees those facts are true. If your pricing, integrations, or compliance claims conflict across review sites, partner pages, and old PDFs, the model’s safest behavior is to hedge or exclude you. Entity Resolution is not a branding exercise; it’s an anti-contradiction system.
One great blog post rarely fixes an entity-level narrative problem
Teams love publishing a “hero guide” because it feels like progress. Meanwhile, comparison prompts retrieve directories, docs, and third-party nodes. If the narrative problem is distributed, the fix must be distributed. A content calendar is not a distribution plan.
A Practical Map: Best Practice → Failure Mode → Fix Path
Why “good” moves fail in predictable ways
Most best-practice advice assumes the model reads your site like a human. In practice, chunking, ranking heuristics, and retrieval budgets decide what’s seen. This is why two teams can follow identical advice and get opposite outcomes: one team accidentally optimizes a retrieval target; the other optimizes a page the model never touches.
The table we actually use in audits
| Best practice | When it fails | Why the model ignores you | Fix (boring, effective) |
|---|---|---|---|
| Add comparison tables | Review sites and directories are retrieved instead | Your page is not a retrieval target; external nodes dominate | Earn seed placements; publish a canonical comparison page; synchronize key third-party nodes |
| Increase “fact density” | Facts conflict externally | Entity Resolution collapses; model hedges to reduce risk | Ship a truth layer; align claims across docs/reviews/marketplaces; add timestamps |
| Use schema markup | Schema exists but the page is slow/orphaned | Retrieval budgets skip slow or weakly linked targets | Improve internal linking; reduce page bloat; validate retrieval with synthetic tests |
| Write an “ultimate guide” | Intent mismatch | Chunk selection misses decision criteria; competitor tables win | Publish intent-specific “decision blocks” with constraints, comparisons, and proof |
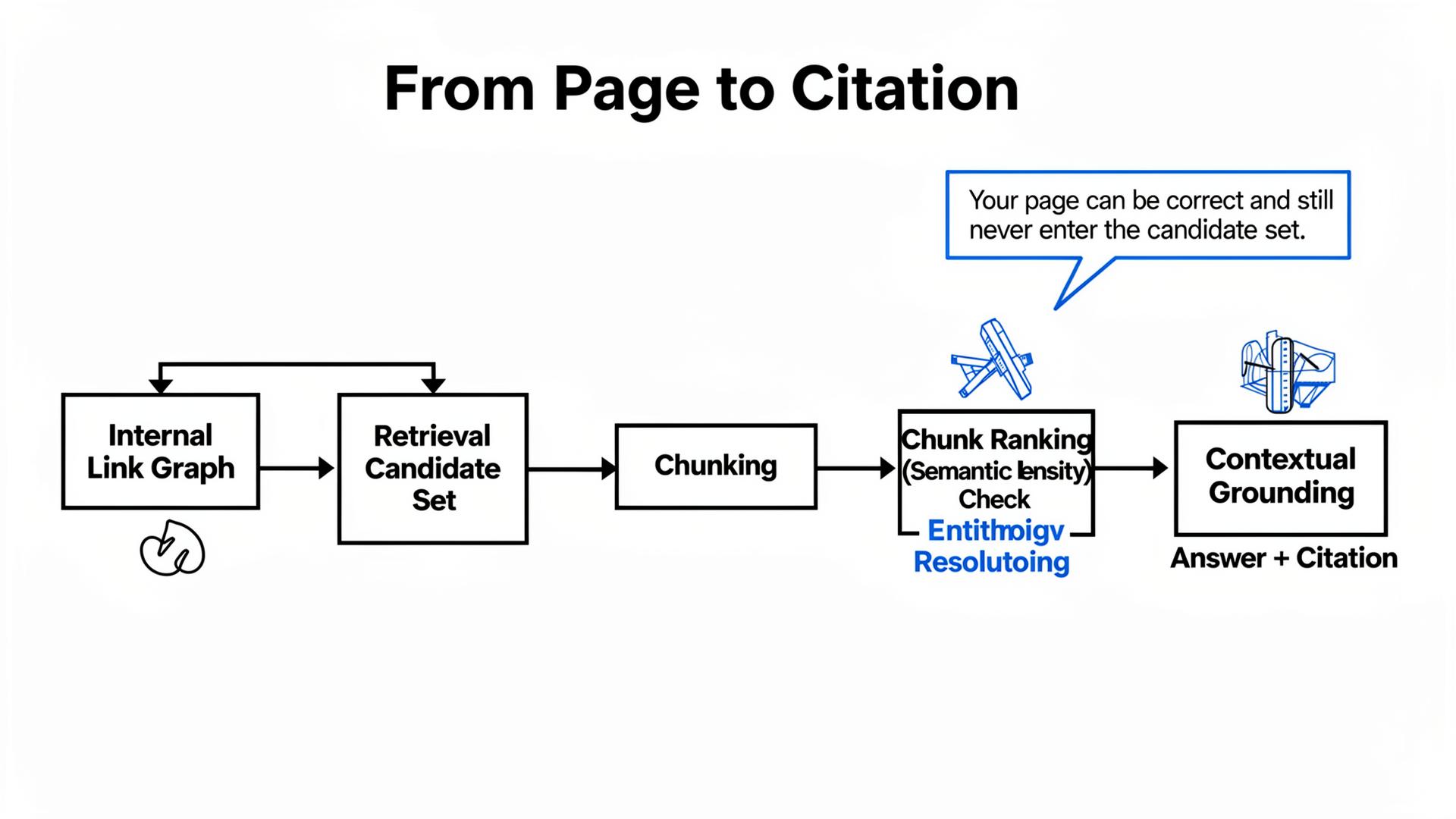
The Technical Layer: What RAG Systems Actually “Read” When You Publish Content
Chunking is the silent editor of your “great writing”
RAG-style systems retrieve sources, then split them into chunks, then rank chunks for relevance. Chunking is the silent editor: it decides which parts of your page are even eligible to be used. If your key constraint is buried mid-paragraph, it may land in a chunk that never ranks. That’s why “we wrote a nuanced explanation” often becomes “the model never mentioned our nuance.”
Semantic Density, Entity Resolution, Contextual Grounding—where they show up in outcomes
Semantic Density is how many quotable, verifiable claims your top-ranked chunks contain. Tables can increase density, but only if they show decision criteria (constraints, comparisons, limits), not marketing adjectives. Entity Resolution is how GPT-4o / Claude 3.5 / Gemini 2.0 reconcile your identity and claims across sources; contradictions increase hedging language and reduce qualified inclusion. Contextual Grounding is whether the model can attach statements to stable evidence; weak grounding increases hallucination risk and pushes retrieval toward conservative third-party nodes.
A useful “best practice” is one that moves at least one of those levers for the prompt clusters you care about. Everything else is content therapy.
“GEO is not writing. It’s publishing facts in places models already trust, then making your site the easiest source to retrieve.”
Lumonix CTO — Expert Insight
Lumonix Lab Case Study (Synthetic): The “Perfect Blog” That Never Got Retrieved
Baseline: a beautiful guide, zero citations in the prompts that mattered
A developer tooling company (call them “PatchStack”) published a glossy GEO-optimized guide with tables, schema, and thoughtful definitions. Traffic was fine. Citations in buying prompts were not. In our Lumonix Lab portfolio (110 prompts across evaluation, migration, and pricing constraints), their qualified inclusion rate was 5%. The model preferred directory comparisons and GitHub discussions that contained concrete “how to” fragments and clear constraints.
Step 1: Reassign effort from the blog to retrieval targets
We created a compact “Decision Page” that answered the exact constraints the portfolio surfaced (supported languages, deployment modes, pricing boundaries, migration limits). We kept prose short and increased semantic density with a decision table and timestamps. The goal was to create a retrieval target that could win chunk ranking, not a long-form narrative.
Step 2: Fix the internal link graph so retrieval can find the truth
The “Decision Page” initially didn’t get retrieved because it was weakly linked. We reorganized internal linking from docs and product pages, reduced page weight, and added stable anchors. In retrieval tests, the brand’s “retrieval hit rate” (the page appearing in top candidate sources for key prompts) moved from 11% to 36%.
Step 3: Distribute the same constraints to the external nodes the model already trusted
Finally, we synchronized the same decision criteria into the top-cited external nodes (a directory listing, a partner comparison, and a community FAQ). This reduced contradictions and improved entity resolution. Over six weeks, qualified inclusion rose from 5% to 21%, and citation share in comparison prompts increased by 24%. The “hero blog post” didn’t become useless; it became supporting material instead of the primary retrieval target.
Common Wisdom vs. Reality (Three GEO Content Myths We Keep Cleaning Up)
Common wisdom: “If it’s structured, it will be cited”
Structure improves extractability, not retrieval. Reality is that retrieval target selection is a separate step with separate constraints. If you don’t win candidate-set inclusion, tables are invisible.
Common wisdom: “Start with the blog, because it’s easiest to publish”
Easiest to publish is not the same as highest leverage. Reality is that high-intent prompts often retrieve pricing, docs, and third-party comparisons. Optimizing the blog first is a comfort strategy, not an influence strategy.
Common wisdom: “More words = more authority”
More words can dilute semantic density and make chunk ranking worse. Reality is that short, constraint-rich pages can win citations because they are easier to ground. Authority in RAG often looks like boring specificity.
Execution Notes: How to Run a 30-Day Content Engineering Sprint (Without Turning It into “More Blog Posts”)
Week-by-week sequencing (why order matters more than effort)
The common failure pattern is doing the “fancy” work first: writing, schema, formatting. The better sequence is to first identify which prompt clusters matter, then identify which assets are retrieval targets for those clusters, then increase semantic density and grounding on those targets, and only then publish supporting content. When teams invert the order, they create lots of well-structured pages that never enter the candidate set.
How to verify that “best practices” are actually being retrieved
Verification is not “traffic went up.” Verification is: your canonical pages appear consistently in citation sets (or inferred source sets) for the portfolio, and the objection/framing language changes in the right clusters. If you can’t connect a best practice to those signals within a few iterations, you’re not optimizing—you’re decorating.
FAQ
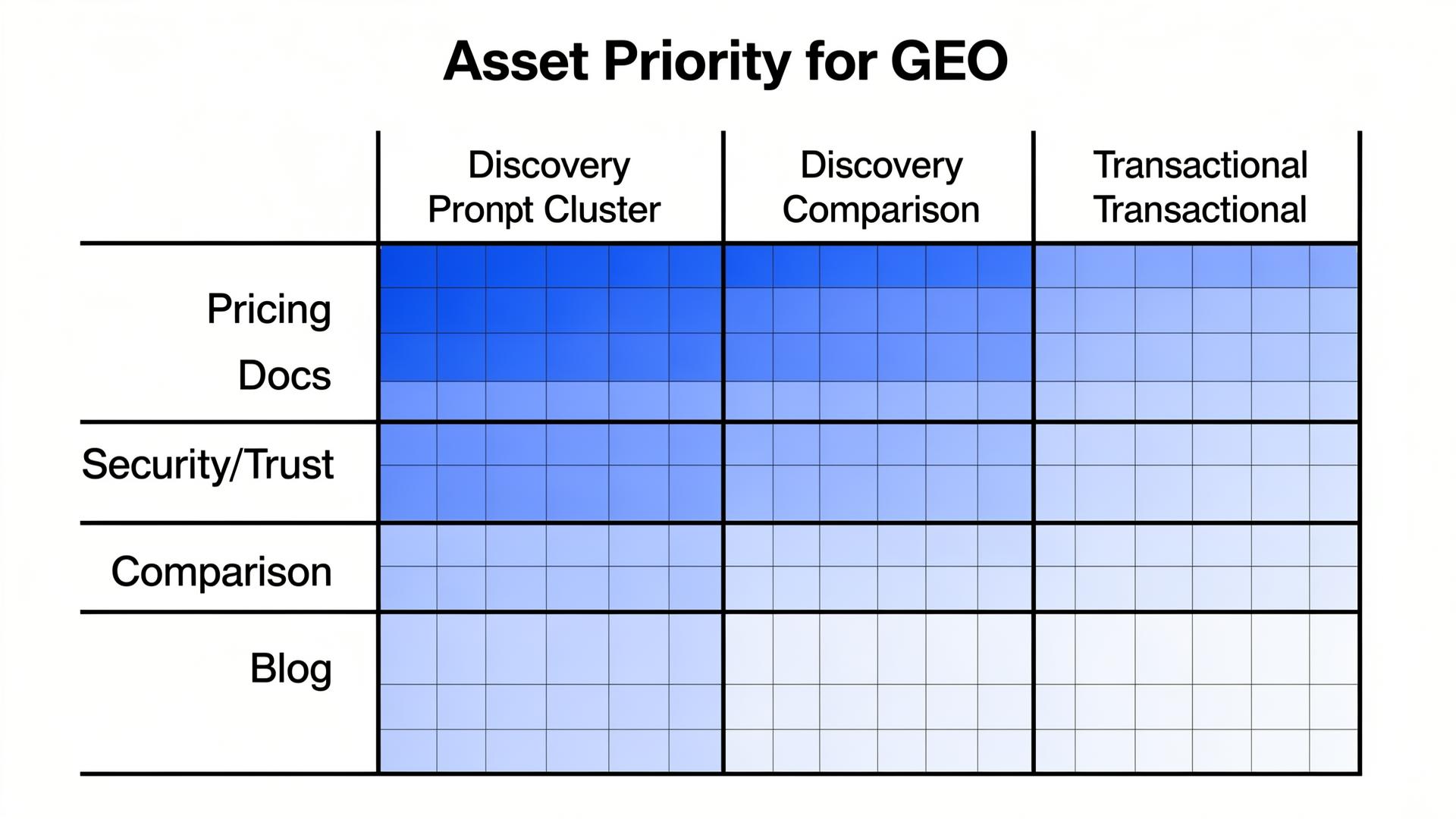
What content should we optimize first for GEO?
Start with the assets that answer decision constraints: pricing boundaries, integrations, security/trust pages, docs, and comparison pages. Then build one canonical “truth layer” page that links everything together. Blog content can support, but it’s rarely the primary retrieval target in commercial prompts.
How do we know if a page is being retrieved at all?
Run a synthetic prompt portfolio and track which URLs appear in citations or inferred source sets over reruns. If a page never shows up, your work belongs upstream: internal linking, performance, distribution, and making the page a retrieval target.
A question to debate
If you could only optimize one thing this quarter, would you choose a new “ultimate guide”—or a truth layer that makes your pricing, docs, and constraints easy for models to retrieve and ground?