GEO vs SEO: The Fight Your Team Is Having (And Everyone’s Losing)
If your org is debating “GEO vs SEO,” congratulations: you’ve discovered a new acronym and accidentally started a religious war inside Slack. The reverse-angle reality is more boring—and more useful. SEO still matters as a legitimacy and retrieval signal, but GEO determines whether a model (GPT-4o, Claude 3.5, Gemini 2.0) uses you as material to assemble answers. If SEO gets you invited to the party, GEO decides whether anyone remembers your name.
The mistake is framing it as either/or. In practice, the two layers interact: crawlability and authority (SEO) affect whether you’re available to retrieval; consistency and extractability (GEO) affect whether you’re selected and quoted. If your team treats GEO as “write more,” you’ll burn budget. If your team treats SEO as “dead,” you’ll lose the retrieval baseline that makes GEO possible.
Key Takeaways (So your team stops arguing and starts shipping)
SEO optimizes retrieval by engines; GEO optimizes selection by models
SEO is about being found and considered by a search engine index. GEO is about being selected and reused by a synthesis system that pulls fragments from multiple sources. One is a ranking problem. The other is a source-selection problem with grounding constraints.
Most “GEO work” fails because it targets the wrong asset type
Teams often optimize the blog because it’s easy to publish. Models often retrieve docs, pricing, reviews, directories, and policy pages for commercial prompts. GEO fails when you optimize the easiest asset, not the most retrieved asset.
Consistency beats cleverness because contradictions trigger risk-avoidance
A single contradictory pricing claim across sources can undo a year of “content.” Models hedge when sources disagree. Hedging reduces qualified inclusion. Fixing contradictions is unsexy but high-leverage.
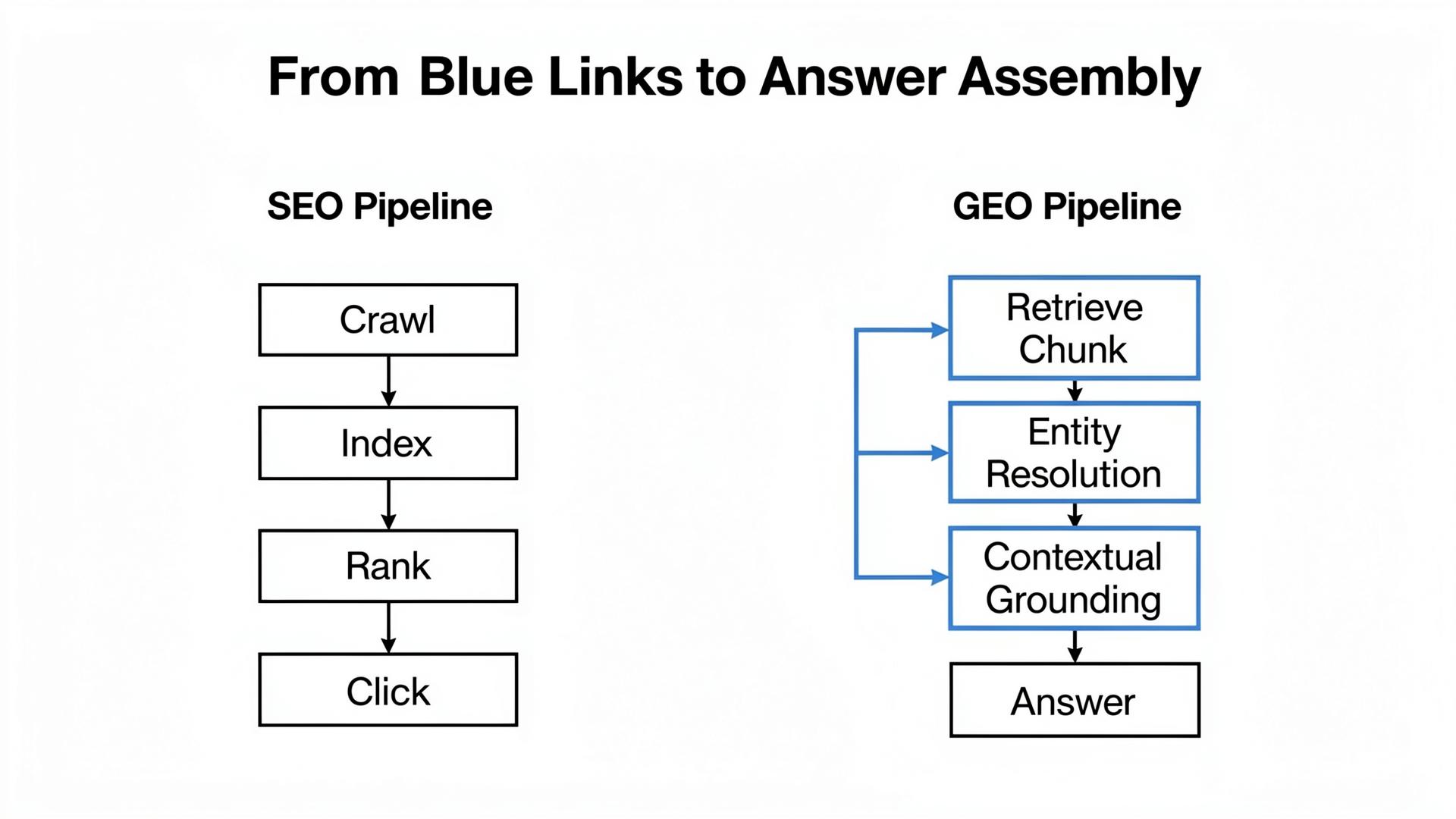
The Shift in Plain English: From “Ranking Pages” to “Feeding Answer Assembly”
Classic SEO: you win with a destination
Classic SEO is destination marketing: rank a page, get a click, convert. Your page is the unit of competition. The user journey is measurable because the click is visible.
GEO: you win with fragments that survive retrieval, chunking, and grounding
In GEO, the unit is often a chunk: a table row, a definition sentence, a constraints paragraph. Models retrieve candidate sources, split them, rank chunks, and then assemble an answer. You’re not just trying to be read; you’re trying to be safely reusable. That’s why a “boring” pricing constraints table can outperform a beautifully written essay.
| Scenario | SEO “win” | GEO “win” | Where teams accidentally lose |
|---|---|---|---|
| Definition intent | Rank “what is X” | Be quoted as the definition | Your definition is buried; chunking hides it from top-ranked snippets. |
| Comparison intent | Rank a “vs” page | Be used as the comparison table | Your page lacks decision criteria; external directories win by having tables. |
| Trust intent | Earn links and reviews | Reduce “unknown/conflicting” answers | Security/pricing facts differ across sources; entity resolution flags risk. |
| Transactional intent | Rank a landing page | Be recommended with constraints | You hide policies; the model guesses, then qualifies you away. |
The Technical Layer: Why Models Behave Differently Than Search Engines
Semantic Density determines whether your content becomes “quotable material”
In model-mediated answers, the winner is often the source with the highest Semantic Density in the top-ranked chunks: extractable, verifiable claims early, not poetic coverage later. This is why “helpful” prose can underperform compared to a constraints table or a crisp FAQ. Models don’t cite tone; they cite structured truth.
Entity Resolution punishes contradictions more than it rewards adjectives
Entity Resolution is the system’s attempt to decide whether “you” across your website, review sites, marketplaces, and partner pages is the same entity with consistent attributes. When attributes disagree, the system reduces risk: hedging language, fewer recommendations, or exclusion. SEO teams often don’t budget for this because it’s not a page-level tactic. GEO teams must.
Contextual Grounding is the boundary between “influence” and “hallucination”
Grounding is how the model ties statements back to evidence. If grounding is weak, the model either invents claims or avoids recommending you. GEO work is often the work of strengthening grounding: canonical truth pages, stable URLs, timestamps, and consistent external nodes that can serve as evidence.
“If your team can’t point to a single page and say: this is our source of truth, models will invent one for you. Spoiler: they usually pick Reddit.”
Lumonix CTO — Expert Insight
Lumonix Lab Case Study (Synthetic): SEO Was Fine. GEO Was a Mess.
Baseline: strong traffic, weak inclusion in buying prompts
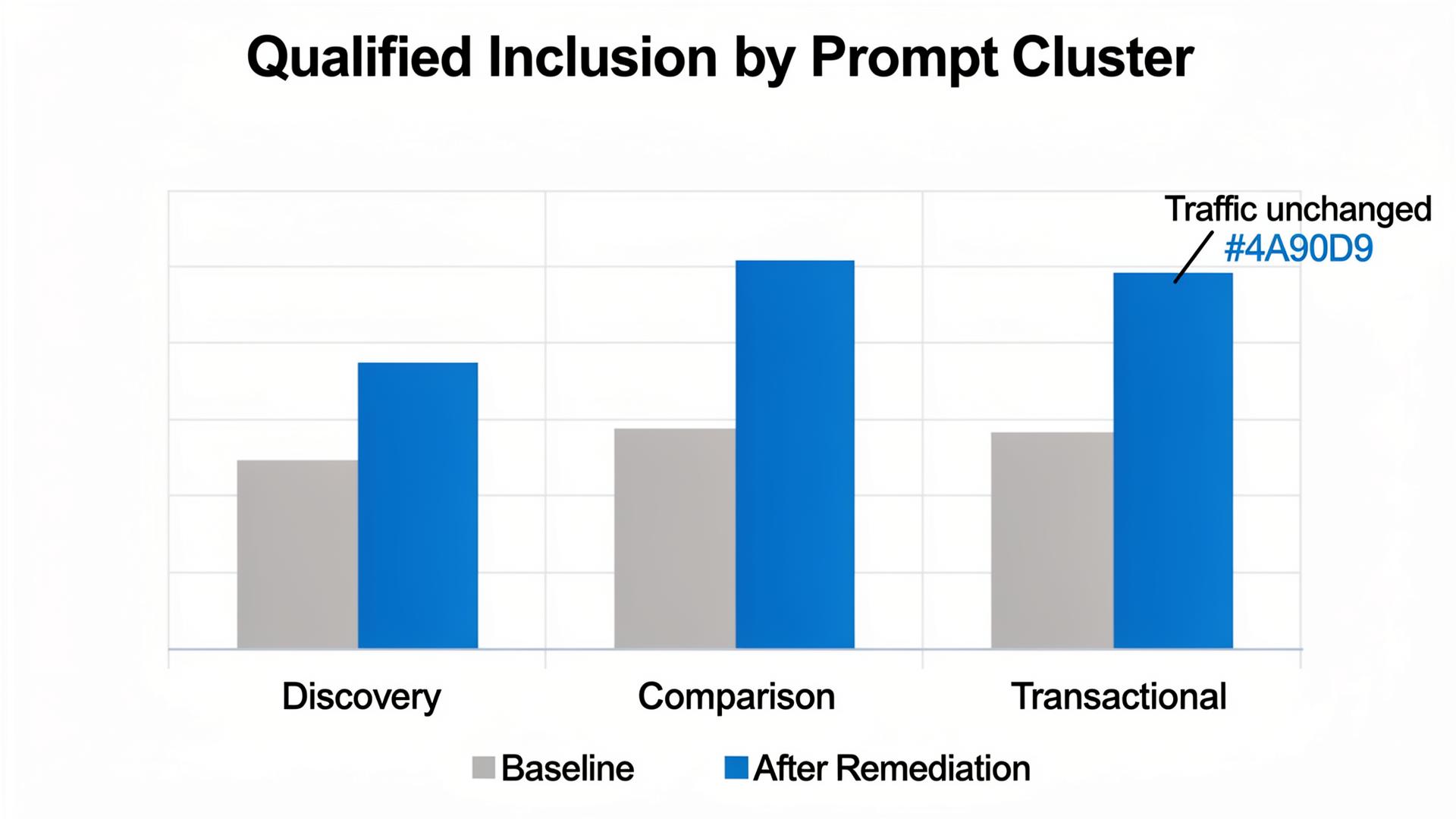
A B2B infrastructure vendor (call them “EdgeHarbor”) had healthy SEO: stable rankings, consistent traffic, and decent conversion rates from classic search. Yet in AI answers for comparison prompts, they were missing. In our Lumonix Lab portfolio of 120 prompts, qualified inclusion was 6%, despite strong SEO authority.
Source mapping showed why: models grounded on a directory table and a third-party review roundup. EdgeHarbor’s own comparison page existed, but it lacked decision criteria (limits, integrations, security proof), and its most important claims were buried in prose that chunking rarely surfaced.
Step 1: Increase extractability (Semantic Density) where chunking can actually see it
We rewired the comparison page into an inverted pyramid: an early constraints table, explicit “who this is not for,” and a compact FAQ with timestamps. We didn’t add 5,000 words. We added decision structure. The page became quotable in the first few chunks.
Step 2: Resolve contradictions across sources (Entity Resolution)
Two external nodes had outdated integration lists and inconsistent pricing language. We synchronized the canonical claims across the top-cited sources and added stable identifiers (plan names, supported regions). The model’s hedging language dropped because the ecosystem stopped disagreeing.
Step 3: Verify grounding improvements with portfolio reruns (Contextual Grounding)
After three weekly remediation cycles, qualified inclusion in comparison prompts rose from 6% to 20%, and citation stability improved as the canonical page became a consistent grounding target. The SEO dashboard looked mostly unchanged. The model’s story changed materially. That’s the point.
Common Wisdom vs. Reality (Why Teams Keep Losing This Debate)
Common wisdom: “SEO is dead”
If SEO is dead, your pages still need to be crawled, indexed, and legitimate. Reality is that SEO is often the prerequisite that makes you retrievable. GEO sits on top of that. Throwing away SEO is like removing your foundation because you want a nicer roof.
Common wisdom: “GEO is just content”
Reality is that GEO is content plus systems: retrieval targets, chunk-friendly structure, entity consistency across sources, and grounding strength. A content-only approach usually produces attractive pages that never become evidence.
Common wisdom: “If we get cited, we win”
Reality is that citations can be irrelevant or negative. Track qualified inclusion and objection framing. Being cited as the expensive risky option is not a win; it’s an early warning.
Operational Peace Treaty: How SEO and GEO Teams Stop Stepping on Each Other
Shared inventory: what assets exist, which ones are retrieval targets
The fastest way to end the “GEO vs SEO” argument is to create one shared inventory of assets and map them to intent clusters. SEO owns crawlability, internal linking health, and baseline authority signals. GEO owns extractability, consistency across nodes, and grounding stability. When teams don’t share the inventory, GEO optimizes pages SEO never prioritizes, and SEO ships pages GEO never structures for extraction.
Shared metrics: a small set both teams can influence
Pick a few metrics that prevent vanity work: retrieval hit rate for canonical pages, qualified inclusion by cluster, objection repetition rate, and source stability. Those metrics force both teams to contribute: SEO improves retrieval eligibility; GEO improves selection and grounding. The debate ends when both teams are measured on the same reality.
FAQ
Where should we start if we have to pick one GEO project?
Start with the source-of-truth layer: pricing boundaries, integrations, security/trust, docs, and one canonical comparison surface. Then distribute those claims to the external nodes that models already cite. Blog content can support discovery, but it’s rarely the first lever in commercial prompts.
How do we prevent the GEO effort from becoming “just write more”?
Tie work to prompt clusters and retrieval targets. If a deliverable cannot plausibly change candidate-set inclusion, chunk selection, or grounding stability, it’s not GEO work. It’s publishing.
A question to debate
If influence increasingly happens without clicks, should teams still be rewarded primarily for traffic—or for measurable improvements in qualified inclusion and reduced objection repetition?